有很多的检索模型,都使用这样的策略:首先使用一种简单的检索模型(比如 LM, BM25 和 TF-IDF)找出最接近 query 的前 N 个结果(比如 top 100/500/1000),然后再使用自己的模型重新对这些结果打分并排序(rerank)。
Author: chiccs
琴月
 在
在  均匀分布,
均匀分布, 是其上的固定点,
是其上的固定点, 

 个坐标轴平行的超平面,将
个坐标轴平行的超平面,将 
 是正则化不完全 Beta 函数
是正则化不完全 Beta 函数

九伤
在  均匀分布, 是其上的固定点,
均匀分布, 是其上的固定点,
定义累积分布 
只考虑 ![x \in [0,1]](https://lxsay.com/wp-content/ql-cache/quicklatex.com-8e2ee4c72e1bf272b34320e708bb7747_l3.png "Rendered by QuickLaTeX.com") 的情形,其它区间置零截断。
的情形,其它区间置零截断。
满足条件的点集构成 上的非球缺,计算它们的测度


荒咬
在  均匀分布, 是其上的固定点,
均匀分布, 是其上的固定点,
定义累积分布
考虑 的情形,其他类似
满足条件的点集构成 上的弧,取它们的测度为 的弧长


NASDAQ:JD 观察
声明:因为消息来源有限,文章内容可能有错漏。若阅读本文进行投资而产生的损益,本人不负任何责任。
京东(NASDAQ:JD)最近因为 CEO Richard Liu 的丑闻以及一些管理上的举措而深陷舆论风波。观点如下:
read more...你找错了地方









DAC with Quad Philips TDA1305T

三四年以前买了自己的第一个解码器,基于 AK4490。出来的声音的解析度很高,现场感不错,但是数码味比较重,声音生冷,就好像没有感情的电子合成器很努力地想发出真实乐器的声音。

NASDAQ:AMD 基本面分析2019
2016:https://lxsay.com/archives/249
2017:https://lxsay.com/archives/697
声明:本文内容仅供参考。因消息来源有限,可能存在错误。因为阅读本文后进行相关投资引起的损益,本人不负任何责任。
在过去的一年,AMD 发布了全新的 Ryzen、EPYC、ThreadRipper 系列处理器,以及 Radeon 系列显卡,成功实现了市场关注度和业绩的双丰收。用流行的话说就是“农企翻身了!”。
现在 AMD 的股价大概在 20~24 美元左右每股。说实话,两年前写下这些文章的时候,正是 AMD 的历史最低谷:Ryzen 将出未出,市场充满怀疑,股价震荡,每个月都能看到机构操盘收割散户的悲惨场面。Intel 和 NVIDIA 为所欲为,没有人相信奇迹。即使我有坚强的意志,看到过山车一般的行情,也不免怀疑自己的预测只是一厢情愿。所幸,最后我们都挺过来了。
分析:
利:1、通过正确的营销策略和渠道建设,大幅提升了市场占有率。营收可观。
2、专注 PC、高性能计算和服务器市场研发,产品线务实,进展稳健。
3、中国大陆游戏市场的解禁带来 PC 业务的大幅增长。
4、个人预测,对超极本、轻薄本、游戏笔记本业务的建设将在未来显现其极端重要性。
5、Intel 的 10nm 工艺遭遇困难
弊:1、显卡方面与英伟达的竞争仍然处于劣势。
2、Jim Keller 跳槽到 Intel。
3、人工智能市场进展缓慢。虽然有 ROCm 平台,但是响应者寥寥。事实上这方面需要强大的推广和渠道建设,并且有一定的自发性。AMD 没必要花大价钱和英伟达恶战,但应该建立自己的存在感。目前没看到务实有效的策略。其实AMD的显卡在 AI 方面的优势在于消费市场的显卡产品价格很低,而且显存很大。RX500 系列的显卡顶配版本一般都有 8G,这正好能达到家用计算机运行神经网络的最大需求。放弃追求适配所有流行框架的想法,转而只支持一款产品(比如 TensorFlow 或 PyTorch)就已经足够。比较讨巧的办法是开发出一个基于 AMD AI 平台 的、并且使用简单的桌面级消费类应用(图像、视频处理、游戏体验优化等等),然后以此为噱头大肆宣传。
4、2019 年前后被一部分人认为是经济周期理论中“经济周期”的最低点,这虽然无法改变世界的运转,但会显著降低不少人对市场的预期。
最后预测股价,短线在 15 美元 ~ 30 美元之间震荡。长线看到 30 美元每股。如果忽略经济周期的影响,长线看到 45 美元每股。
七碗面
临近周末,飞的打到杭州,住进西湖边的玉皇山。
山风呼啸,绿树环绕,我仿佛也成为自然里漂浮的空气,无所牵挂。心情好了很多。
很久以前,我对某人说,我要做片儿川给你吃。这次来杭州,有个很重要的任务就是品尝比较正宗的片儿川。
傍晚,从酒店出发,沿莲花峰路往玉皇山路方向走几百米,在丝绸博物馆的对面,有一家叫“七碗面”的面馆。






TREC CAR 2018 随想
结果如何?直接看图吧。
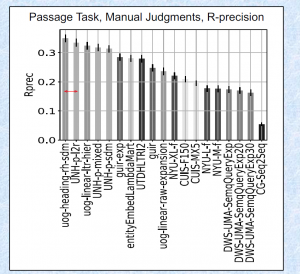
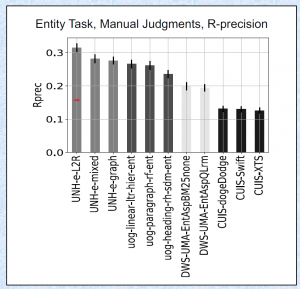
今年春节的时候就想开发一个比去年更好的方法。一直被阻拦,只能断断续续地做实验。在 cikm 交稿之后,离 trec 的 deadline 只剩一两周的时候匆忙继续。发现了 Wikipedia article information 可以增强性能。总算有东西可以提交。
这个 task 有几个比较奇特的地方:
一是输入输出格式比较复杂,要自己用 trec-car-tools 从 cbor 里面读取每个 query path。这两年还有区分 query 的类型,比如 outlines(文章标题), hierarchical(最具体的章节路径)。输出的时候要加上 “enwiki:” 或者 “tqa”这样的前缀。 说实话不能理解为什么要这么折腾。
二是这个任务的 evaluation 其实是有偏差的 (biased)。 评估方式分三种 Automatic, manual 和 lenient。Automatic 就是用维基百科的章节路径当作 query,然后章节里面包含的段落当作 ground truth。 manual 和 lenient 是按照 trec 标准的人工评测。 个人发现 SDM 类的模型经过充分的调参以后可以在 automatic 上取得 state-of-the-art 的结果,但是 manual 和 lenient 的评测结果和其他方法比就还有差距。 这其实反映了统计语言模型和 neural ranking model 对 concept salience 的假设是不一样的。
三是我这次用 Wikipedia article 的信息作为一个特征输入,由于程序的一个 bug,这个部分全部输出为0,结果竟然还比没有集成这个特征的原始模型提升了至少 15%。这起码说明能找到对应 Wikipedia article 的段落更有可能成为答案。我感觉 Laura 可能已经发现了这个问题,后续的数据集应该会变得更加 Wikipedia-free。
反正结果就是这样,这次其他的队伍用了很多成熟的 learning to rank 的方法,再加上一些 hand-crafted feature 和 query expansion mechnism(比如 RM3。。。)。取得好的结果是意料之中。恭喜。
我十月份申请的美签居然还在 administrative processing! 最后没去参加 trec。只好给 Laura 发邮件解释原因,给 hilton 发邮件取消房间,交 no-show charge,取消机票。我很讨厌处理这种琐事,这次耗尽了所有精力。 us visa office seems to believe that the higher education a Chinese get, the more dangerous is he or she to the United States. This is truly ridiculous and racist. 另外美国香港领事馆是我见过的服务态度最恶劣的领事馆,只能说人在做天在看。非常失望,这辈子都不考虑去美国。
总的来说今年的这件事算是彻底的失败了。但这不是我的失败,也不是我的耻辱。我只是在有限的时间里做了自己能做的所有事情。有些阻碍不是我能跨越的,有些装睡的人不是我能叫醒的。如果一百年以后的哪天我死了,我的墓碑上也许会有一句话:此人此生光明磊落。