结果如何?直接看图吧。
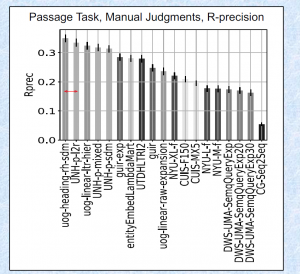
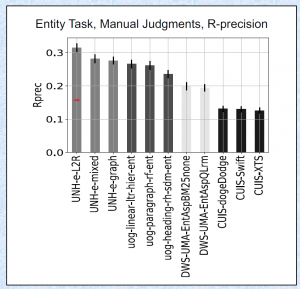
今年春节的时候就想开发一个比去年更好的方法。一直被阻拦,只能断断续续地做实验。在 cikm 交稿之后,离 trec 的 deadline 只剩一两周的时候匆忙继续。发现了 Wikipedia article information 可以增强性能。总算有东西可以提交。
这个 task 有几个比较奇特的地方:
一是输入输出格式比较复杂,要自己用 trec-car-tools 从 cbor 里面读取每个 query path。这两年还有区分 query 的类型,比如 outlines(文章标题), hierarchical(最具体的章节路径)。输出的时候要加上 “enwiki:” 或者 “tqa”这样的前缀。 说实话不能理解为什么要这么折腾。
二是这个任务的 evaluation 其实是有偏差的 (biased)。 评估方式分三种 Automatic, manual 和 lenient。Automatic 就是用维基百科的章节路径当作 query,然后章节里面包含的段落当作 ground truth。 manual 和 lenient 是按照 trec 标准的人工评测。 个人发现 SDM 类的模型经过充分的调参以后可以在 automatic 上取得 state-of-the-art 的结果,但是 manual 和 lenient 的评测结果和其他方法比就还有差距。 这其实反映了统计语言模型和 neural ranking model 对 concept salience 的假设是不一样的。
三是我这次用 Wikipedia article 的信息作为一个特征输入,由于程序的一个 bug,这个部分全部输出为0,结果竟然还比没有集成这个特征的原始模型提升了至少 15%。这起码说明能找到对应 Wikipedia article 的段落更有可能成为答案。我感觉 Laura 可能已经发现了这个问题,后续的数据集应该会变得更加 Wikipedia-free。
反正结果就是这样,这次其他的队伍用了很多成熟的 learning to rank 的方法,再加上一些 hand-crafted feature 和 query expansion mechnism(比如 RM3。。。)。取得好的结果是意料之中。恭喜。
我十月份申请的美签居然还在 administrative processing! 最后没去参加 trec。只好给 Laura 发邮件解释原因,给 hilton 发邮件取消房间,交 no-show charge,取消机票。我很讨厌处理这种琐事,这次耗尽了所有精力。 us visa office seems to believe that the higher education a Chinese get, the more dangerous is he or she to the United States. This is truly ridiculous and racist. 另外美国香港领事馆是我见过的服务态度最恶劣的领事馆,只能说人在做天在看。非常失望,这辈子都不考虑去美国。
总的来说今年的这件事算是彻底的失败了。但这不是我的失败,也不是我的耻辱。我只是在有限的时间里做了自己能做的所有事情。有些阻碍不是我能跨越的,有些装睡的人不是我能叫醒的。如果一百年以后的哪天我死了,我的墓碑上也许会有一句话:此人此生光明磊落。
住希尔顿,厉害了
一看ip我就知道是谁了。。。