Even a statistical language model can “prompt” (i)
read more...
写下就是玩,少一些阴暗的心态,可以让自己的生活充满更多乐趣,多活几年。否则坐议立谈,无所不能,好似蔡澜叹名菜——可人家是才子兼美食家蔡澜,我们只是“卑鄙病态的、荒淫空虚的家伙”(《论历史上的英雄、英雄崇拜和英雄业绩》,托马斯·卡莱尔)。
考虑一个简单的,统计的语言模型,比如 KenLM 所用的 backoff-smoothed LM:
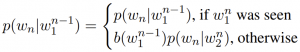
(我打工的时候非常喜欢用 KenLM,唯一问题是生成的模型大小惊人,有一次我在一个腾讯云的节点上部署了一个 40G 大小的 KenLM 模型,每次启动节点至少要花两分多钟。其实有一些技术可以压缩它的文件体积)
给定一段文字,使用这样的模型生成文字,同样是枚举词汇表,计算出生成概率最大的 token 然后输出。
这个简陋的生成模型当然无法与神经语言模型抗衡,即使稍加改造,写成一个概率图也是如此。因为它只使用显式的计数和顺序信息。现在思考什么情况下这样的模型还能取得合理的性能?这变成一个文学问题:什么样的文体适合这样的书写方式?直白的、语句短小的、祈使的和时态一致的文本。
 ,
, 


