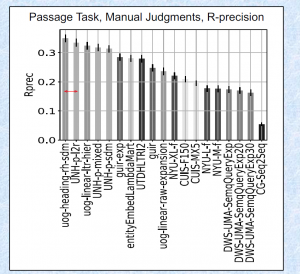
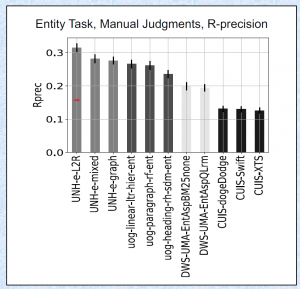
EYRE’18 就是 “1st International Workshop on EntitY REtrieval (EYRE ’18)”
因为我那天在都灵睡过头了,错过了一些 presentation,所以只谈几个我感兴趣的。
1. Graph Analytical Re-ranking for Entity Search. Takahiro Komamizu
文章和之前评论的内容差不多,我甚至有点怀疑作者是看了我的评论才把这个方法叫做 “Personalized Pagerank based score distribution”。这个方法是否本质有效,不想说了,最近心情不好。
(说点不好听的吧,这其实是我三年前玩过的东西,研究我的 github 项目的人会发现,我的框架里面总有一个 createGraph 模块,就是给这个东西用的。为什么我没写文章讲这件事呢?自己想想吧)
Anyway, consider entities together 是有价值的想法。
2.Annotating Domain-Specific Texts with Babelfy: A Case Study. Michael Färber, Kristian Noullet and Boulos El Asmar
对文章内容不评价。讲一些趣闻:年初我参加 ECIR2018 找 Adam Jatowt 尬聊 NTCIR AKG 的时候看到 Michael 也在旁边,当时还以为他是 Adam 的学生,抢占了他几分钟时间,真是抱歉。。。个人看好这个小帅哥,感觉他是个比较踏实的人。
3.Graph-based Reranking Approach for DBpedia Entity Search. Bo Ma, Yating Yang, Tonghai Jiang, Xi Zhou and Lei Wang
我个人认为,作者提出来的方法本质是借鉴 Discounted Cumulative Gain 的思想来 rerank 所有结果。当然,他在 slides 里面说 “more links, more important”这种解释也还算说得过去,其实和 DCG 的思想是一样的。不过比较讽刺的是这个模型在 QALD2 和 SemSearch 上的结果很差,有点违背了他的解释。
为什么大部分模型都会有 “results are dataset specific” 的情况呢? 不想说了,最近心情不好。
update 2019/03. 最近考虑了一下,感觉更像是从 pagerank 这类基于重要性的模型中得到灵感。NDCG 作为一种评价方式和 pagerank 有一些形式上的相同,这反而让我觉得有些意思。
4.Exploring Summary-Expanded Entity Embeddings for Entity Retrieval. Shahrzad Naseri, John Foley, James Allan and Brendan T. O’Connor
训练了一个 word-entity 的 embedding,embedding 的分数和 FSDM 的分数加权平均。不想说什么。
我觉得最不高兴的点就是这些人好像根本没有注意到 term-based retrieval model 的地位。另外好像也没读我的 ECIR 和 ICTIR 的文章,更别说引用了。(这并不是说我的文章有多么好或多么重要,而是在你准备做相关的研究的时候至少应该看看最近这个领域的人在谈论什么。)
总的来说这次研讨会的 entity search 部分就像一个大型民科自嗨现场,没有特别有效的进展。不过 Prof. Gong Cheng 花了很多时间尽力让这个会议变得正式和专业,作为开拓者劳苦功高,什么都干不了的小弟在此表示衷心感谢和敬意。期待下次变得更好。
 上的内积和测地线的性质。看到这篇文章的第二节的前两段的时候,我觉得自己不用再写这些东西,直接抱大腿、用现成的模型就行。但作者紧接着只是介绍自己提出的 SphereConv 这个卷积层。
上的内积和测地线的性质。看到这篇文章的第二节的前两段的时候,我觉得自己不用再写这些东西,直接抱大腿、用现成的模型就行。但作者紧接着只是介绍自己提出的 SphereConv 这个卷积层。 ,求连接
,求连接  和
和  的测地线(geodesic)的长度。
的测地线(geodesic)的长度。 计算小于等于
计算小于等于  的那部分弧长。通过
的那部分弧长。通过 

 个坐标轴平行的超平面,将
个坐标轴平行的超平面,将 
 是正则化不完全 Beta 函数
是正则化不完全 Beta 函数

 均匀分布,
均匀分布,
![x \in [0,1]](https://lxsay.com/wp-content/ql-cache/quicklatex.com-8e2ee4c72e1bf272b34320e708bb7747_l3.png "Rendered by QuickLaTeX.com") 的情形,其它区间置零截断。
的情形,其它区间置零截断。

 均匀分布,
均匀分布,