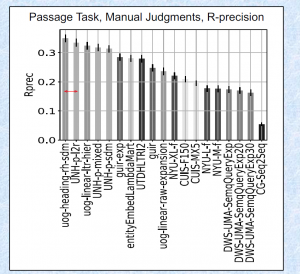
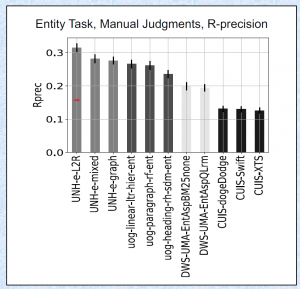
“流形检索”提要。
最近,我写的一篇文章进了 SIGIR 2020 这个会。它很短,对我来说是一个“锚”,这样以后写作的时候起码有资料可以引用,不用像民科一样没有根据地长篇大论。
这篇文章只想讲一件事:在连续的集合上可以定义“语言”。如此,所谓的“神经排序”就是连续点集上的统计语言模型,因此所谓的“end-to-end” 就是内蕴的性质。“结构”(structure)与“测度”(measure)是“新语义检索”的基础,它们分别概括了“表示法”(representation)和“模型”(retrieval model)这两个传统的概念。它必须收敛,收敛性是模型正确性和性能的一种估计。有些公司的什么“技术博客”总喜欢吹嘘“数据决定模型性能”这类有机械唯物主义意味的观点,奉之为“指导思想”,把自己的命运完全交给收集用户偶然的行为(这些用户行得通,那些用户呢?当然可以说自己的模型都能奏效,但这就不只是数据的问题),还有对 learning-to-rank 望文生义的涂改,不想多说,专心做生意吧。
流形上的概率论很早就有了,这与信息几何(information geometry)的发展有关,只是它们研究的大多都是参数空间的分布,本文反而考虑变量空间的事情。以前那些形如“xx learning/clustering on manifold”的文章,为了让梯度可以直接在曲面上更新,一定会用指数映射之类的方法。这些画蛇添足的内容我全都放弃了。从某种意义上说,直接更新梯度之后再把向量归一化再算测度,是一种“传输”,这暗示了那些 xx norm 之类的方法真正的含义。还有一些譬如 ngram 表示之类的问题,可以在复流形上解决,也可以用一些像向量一样的东西代替。
其实,这也和量子检索(quantum retrieval)有关,只是前面的人比较极端,试图用量子力学直接概括整个领域。
这篇论文的写作和发表可能得到了无法知晓的支持,在此顺带以真诚致谢。我从不打算靠做此类研究谋生。这个时代,智力正常的人都应该想出一百种赚钱的方式,在每个行业只要花足够多的时间和毅力,最后都能得到可观的财富,做到底就知道这其实是国家实力发展的结果。在一个动荡的社会里很难静下心来做事,这是我暂时离开香港的原因,无法一直在负面的情绪中工作和生活,这会扭曲人的心灵,神智将和社会一样撕裂。但我会认为,这篇论文是给香港社会的答谢,尽管它没有了不起的内容,我也只是很渺小的一个人,能够没有负担地走出去。
这是“拳皇”系列博文的结束,台湾知名格斗游戏选手“Nikolai 保力達”的视频给了我很多的乐趣,过段时间再写下个系列。
 ,文档
,文档  。假定
。假定  上有
上有  个初始点各自符合分布
个初始点各自符合分布  ,还有
,还有  个点表示文档词的位置。
个点表示文档词的位置。 。把
。把  。
。 使用“路径选择器”
使用“路径选择器” 

 个核函数。如果设计得当,
个核函数。如果设计得当,  与文档集,排序模型对文档集的所有文档打分,并产生长度为
与文档集,排序模型对文档集的所有文档打分,并产生长度为  满足
满足  。
。 是搜索结果中第
是搜索结果中第  位的文档的排序分数。
位的文档的排序分数。 中良好定义的,应该满足:
中良好定义的,应该满足:
 张成的空间中,任意
张成的空间中,任意  都是定义在此空间的函数,于是上式是指
都是定义在此空间的函数,于是上式是指 
 函数 的 Jacobian 矩阵是对称的。如果损失函数
函数 的 Jacobian 矩阵是对称的。如果损失函数  ,定义 1-形式
,定义 1-形式  。
。 可以看作是一个“有向的”微元。 LambdaRank 的假定可以写成
可以看作是一个“有向的”微元。 LambdaRank 的假定可以写成  ,
, 是外微分。想要找到满足假定的一般的
是外微分。想要找到满足假定的一般的  当且仅当
当且仅当  上的内积和测地线的性质。看到这篇文章的第二节的前两段的时候,我觉得自己不用再写这些东西,直接抱大腿、用现成的模型就行。但作者紧接着只是介绍自己提出的 SphereConv 这个卷积层。
上的内积和测地线的性质。看到这篇文章的第二节的前两段的时候,我觉得自己不用再写这些东西,直接抱大腿、用现成的模型就行。但作者紧接着只是介绍自己提出的 SphereConv 这个卷积层。 在
在  是其上的固定点,
是其上的固定点, 

 个坐标轴平行的超平面,将
个坐标轴平行的超平面,将 
 是正则化不完全 Beta 函数
是正则化不完全 Beta 函数